



Intelligence artificielle et imagerie : une plateforme Open Source pour se lancer
Catégorie: Cartographie, Données, Imagerie, Logiciels, Open Data, Reportages, Satellite/Spatial
820 mots, environ 3 mn de lecture
Le potentiel des algorithmes d’intelligence artificielle dans le domaine de l’information géographique est désormais reconnu. Mais comment se lancer ? DataPink propose une plateforme dédiée à l’imagerie spatiale en Open Source. Les premiers résultats sont encourageants et ne demandent qu’à être améliorés par la communauté.
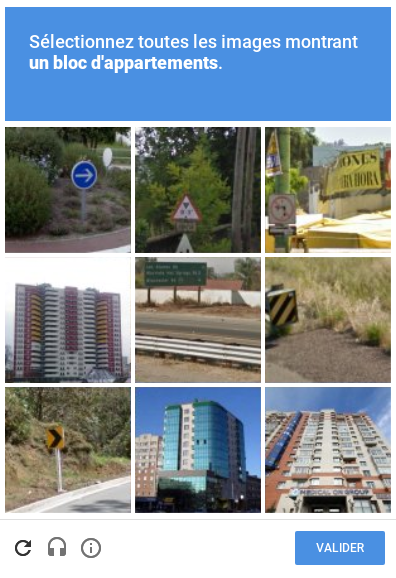 « Veuillez sélectionner les images montrant une voiture / une montagne / une devanture de magasin / un panneau de signalisation… » : Qui n’est pas tombé sur ce genre de captcha visuel au moment de s’inscrire sur un site ou de télécharger un document ? Derrière ce petit exercice de sélection qui garantira à Google votre humaine nature, se cache un problème crucial pour l’intelligence artificielle : disposer d’un jeu d’apprentissage conséquent. En effet, pour que les réseaux neuronaux (qui sont à la base de l’intelligence artificielle) reconnaissent un objet ou détectent un changement, ils doivent d’abord ingérer des couples d’images et de labels, où l’objet en question est clairement identifié. L’algorithme apprend alors progressivement à reconnaître les objets ou motifs souhaités en s’améliorant à chaque tentative.
« Veuillez sélectionner les images montrant une voiture / une montagne / une devanture de magasin / un panneau de signalisation… » : Qui n’est pas tombé sur ce genre de captcha visuel au moment de s’inscrire sur un site ou de télécharger un document ? Derrière ce petit exercice de sélection qui garantira à Google votre humaine nature, se cache un problème crucial pour l’intelligence artificielle : disposer d’un jeu d’apprentissage conséquent. En effet, pour que les réseaux neuronaux (qui sont à la base de l’intelligence artificielle) reconnaissent un objet ou détectent un changement, ils doivent d’abord ingérer des couples d’images et de labels, où l’objet en question est clairement identifié. L’algorithme apprend alors progressivement à reconnaître les objets ou motifs souhaités en s’améliorant à chaque tentative.
Il a ainsi fallu analyser des millions d’images de sourires labellisés pour que votre appareil dernier cri sache prendre la photo au bon moment. Devant leurs ordinateurs, des centaines de milliers de petites mains s’attellent à cette tâche immense, plus ou moins consciemment. C’est ainsi que Google vous met au travail grâce à ses captchas, tandis que Facebook entraîne son algorithme à l’aide des photos postées sur Instagram. Encore largement manuel, ce travail se fait parfois au sein de communautés de chercheurs (comme ImageNet) ou contre rémunération (modeste) grâce par exemple au Mechanical Turk d’Amazon.
Comment s’entraîner dans le domaine géographique ?
Faire défiler des milliers d’images satellitaires ou aériennes et pointer sur les maisons, les routes, les piscines… ne tente personne. Pourtant, un jeu d’entraînement trop réduit, ou pire imprécis, limitera l’efficacité des algorithmes.
Pourquoi ne pas s’appuyer sur des bases de données déjà constituées pour fournir les échantillons d’entraînement ? Ainsi le bâti déjà vectorisé semble idéal pour entraîner un algorithme de détection de bâti… tant que la base vectorielle est parfaitement à jour, en totale cohérence avec l’imagerie, ce qui est rarement le cas. BD Topo, OpenStreetMap, cadastre… de nombreuses sources sont aujourd’hui mobilisables, notamment en Open Data, mais elles ont toutes leurs imperfections.

Avec RoboSat.pink, Olivier Courtin propose une plateforme pour faciliter l’émergence d’algorithmes d’intelligence artificielle ouverts et locaux.
DataPink, créé par Olivier Courtin il y a 18 mois, propose justement une plateforme logicielle Open Source destinée à constituer des données d’apprentissage et à entraîner les algorithmes d’apprentissage profond : RoboSat.pink. Elle facilite d’une part la récupération de flux de données (orthophotographies, images satellitaires, bases vectorielles) en s’appuyant notamment sur les standards de l’OGC). Elle permet également d’accéder à des briques d’algorithmes « à la pointe de l’état de l’art, utilisés aussi bien en imagerie médicale et spatiale, qu’en conduite autonome… » précise Olivier Courtin.
Beaucoup d’automatisme et un bon coup d’œil
L’exemple présenté sur Github s’appuie sur les données du Grand Lyon, qui publie en Open Data une couche vectorielle des empreintes de toits. L’image aérienne à analyser est découpée en tuiles sur lesquelles la couche vectorielle est superposée. L’algorithme d’intelligence artificielle s’entraîne ensuite avec les données brutes. Puis convergences et divergences sont analysées visuellement. L’utilisateur élimine manuellement les tuiles trop divergentes en raison d’une labellisation imparfaite (mauvaise classification, problème de mise à jour…) et relance l’algorithme avec un jeu de données d’apprentissage épuré, en vue d’obtenir un meilleur score de reconnaissance.
« Cette approche en deux temps permet de parfaire et de qualifier le jeu d’apprentissage, mais également de pouvoir ‘se lancer’ avec des données d’ores et déjà disponibles en Open Data » insiste Olivier Courtin.

En rose : zones prédites par l’algorithme (mais non présente dans la base d’entraînement)
En vert : zones présentes dans la base d’entraînement mais non reconnues par l’algorithme
En gris : zones prédites par l’algorithme et présentes dans la base d’entraînement
L’ouverture du code et sa modularité vont également aider des laboratoires de recherche à faire évoluer certaines briques algorithmiques et d’agir prioritairement sur deux éléments essentiels : la topologie du modèle et les fonctions de coûts. Deux domaines décisifs pour atteindre des bons niveaux de performance, actuellement au cœur de la recherche en vision par ordinateur, publique ou privée.
Les utilisations possibles de RoboSat.pink peuvent concerner de nombreux domaines applicatifs. Repérer rapidement des zones d’incohérence ou détecter des changements peut par exemple alimenter ensuite un processus de contrôle qualité.
La suite logicielle proposée n’assure pas encore l’extraction des données (reconstitution de fichiers vectoriels), mais c’est prévu sous peu, et Olivier Courtin est également ouvert à tout partenariat permettant de faire progresser plus rapidement RoboSat.pink, le premier des projets de recherche et développement de DataPink à arriver au stade industriel. « Sur ces sujets, conclut le développeur, la compétition n’est plus entre les structures de l’écosystème SIG, mais avec, ou plutôt contre, les GAFAM. »


 Communiqués
Communiqués 




