



En route vers le Web sémantique ?
Catégorie: Données, Logiciels, Open Data, Reportages, Standards, Utilisateurs, WebMapping
Voilà plusieurs années que le Web sémantique occupe une place de choix dans les colloques scientifiques et les articles de presse. Mais de quoi s’agit-il exactement et en quoi cela concerne l’information géographique ? La journée interopérabilité et Innovation organisée le 7 octobre dernier par l’Afnor, l’OGC et GDR Magis a apporté quelques éléments de réponse.
Dès 1994, Tim Berners-Lee, le père du Web, introduit le concept de Web sémantique. L’idée était que les machines allaient être capables d’interpréter seules les informations circulant sur la toile. Certains ont alors eu peur que les machines apprennent à se passer des hommes, réveillant le spectre des Matrix et autres IA incontrôlables. Même si le Web sémantique hérite de trente ans de travaux sur l’intelligence artificielle, les experts préfèrent parler de Web des données, voire de Web des données liées.
De la sémantique et des données liées
Car l’objectif principal du Web sémantique est de permettre aux logiciels et autres applications du Web de comprendre le sens des données exploitées afin de fournir des réponses mieux ciblées. Comme nous butinons sur la toile de lien en lien pour enrichir notre expérience de navigation, les ordinateurs seront capables de relier toutes sortes de données, de vérifier qu’elles décrivent bien les mêmes objets du monde réel, d’intégrer la logique de leurs relations afin d’enrichir les réponses aux questions que nous leur posons. Tout cela en s’appuyant sur une pile de standards mis peu à peu en place par le W3C, l’instance de standardisation du Web, qui garantit que les objets et ensembles logiques d’objets sont bien décrits par des données de façon unique, précise, stable, cohérente et adaptée aux fonctions envisagées.

Les standards du Web sémantique sont de plusieurs ordres. Les premiers garantissent une identification cohérente des données (URI) et de leurs relations (RDF) en s’appuyant sur des ontologies normalisées (OWL et RDF-S). Les deuxièmes permettent alors d’effectuer des requêtes (SPARQL). D’autres couches se chargent de valider les résultats des requêtes au sein d’interfaces utilisateurs (d’après Fabien Gandon « Quand le lien fait sens »).
La géo a aussi besoin du sémantique
Même si le sujet peut paraître très informatique, il concerne les producteurs et consommateurs d’information géographique, un domaine qui pratique beaucoup les échanges de données entre professions très différentes. « Rien qu’à l’USGS (US Geological Survey), commentait Bart de Lathouwer de l’OGC (Open Geospatial Consortium), il y a plus de dix mille termes différents pour désigner une source d’eau souterraine. » François Robida, membre du conseil d’administration de l’OGC renchérit : « Les aspects sémantiques sont au cœur des problématiques OGC aujourd’hui. La ville intelligente est, par exemple, un domaine multi-acteurs, où chacun a son point de vue sur les différents objets qu’il utilise et où le partage de données est crucial. »
Le consortium souhaite apporter sa pierre à l’édifice des standards qui donnent vie au Web sémantique, un sujet à l’étude depuis 2006. Il a publié un standard GeoSPARQL, qui pourrait faciliter la création/gestion d’ontologies dans le domaine géographique. Un sommet sur la géosémantique est également prévu pour 2015. Le TC/211, instance de normalisation européenne, travaille pour sa part sur la création d’ontologies OWL pour l’information géographique respectant les règles ISO (19150-2).
Pas de géosémantique sans ontologies
Le travail sur les ontologies est crucial pour le Web sémantique : « La sémantisation des données ne peut s’envisager en dehors d’un contexte métier précis. D’où la nécessité d’une brique qui permet de formaliser les connaissances sur un secteur précis. Une ontologie implique qu’une communauté se mette d’accord sur une connaissance explicite et formelle. Elle doit donc comprendre à la fois un vocabulaire contrôlé et l’ensemble des contraintes logiques associées à ce vocabulaire. C’est un modèle qui représente un savoir ou un savoir-faire, un peu comme les schémas UML représentent le fonctionnement d’un système » détaille Christophe Cruz, professeur à l’université de Bourgogne et membre du laboratoire Électronique informatique et Image (LE2I).
Et c’est bien à ce niveau que les utilisateurs d’information géographique peuvent agir, comme l’ont montré les présentations de la journée. Ainsi, la Covadis a mis au point un thesaurus intégrant trois vocabulaires pour faciliter le pointage vers les différents thèmes INSPIRE : un vocabulaire des concepts juridiques et statistiques, un vocabulaire des politiques publiques ainsi que VocInspire, le vocabulaire des concepts INSPIRE tels que définis dans le règlement interopérabilité de la directive. En explicitant la correspondance entre « poste de gué DFCI », « petite région agricole » ou « zone vulnérable aux nitrates » et les thèmes INSPIRE correspondants, il va faciliter le pointage dans les fiches de métadonnées. Il est aujourd’hui proposé sous forme de simple page html, intégrée dans le Géocatalogue « mais devrait prochainement être intégré directement dans Geosource », promet Benoît David du ministère de l’Écologie. VocInspire, pour sa part, est disponible dans toutes les langues de l’Union européenne, ce qui devrait faciliter les recherches dans les catalogues de métadonnées. Côté SINP, un gros travail a été effectué pour définir des identifiants stables dans le temps. Des vocabulaires contrôlés ont également été élaborés afin de normaliser la saisie des données et faciliter la consolidation des nombreux jeux de données produits aux échelles locales. Mais on est encore loin des ontologies en OWL ou RDFS. Au Sandre, qui gère le système d’information sur l’eau qui regroupe de nombreuses données produites par différents organismes, là aussi des dictionnaires existent (30 000 éléments sont codifiés), complétés par des fiches de spécifications (3 000). Les fiches sont disponibles en PDF mais des modèles UML existent également.
Côté recherche
Le séminaire fut également l’occasion de découvrir quelques projets de recherche intéressants. Datalift, présenté par l’IGN, a permis de créer une plateforme facilitant la publication sur le Web des données. Les équipes impliquées dans le projet ont par exemple référencé les différentes ontologies et vocabulaires touchant à l’information géographique (dans ses composantes géométriques et géographiques) et proposent des outils d’aide à la création de vocabulaires. Certaines entités administratives, de la toponymie et les systèmes de coordonnées de l’IGN ont également été publiés sous forme d’URI réutilisables.
Christophe Cruz a également présenté plusieurs projets de l’équipe Checksem, qui exploitent les concepts du Web sémantique lié à des données géographiques. « Dans le projet Continuum, nous travaillons sur la modélisation de l’évolution spatio-temporelle des parcelles, ce qui va nous permettre d’identifier des modèles. Par exemple, une route qui borde une zone qui a subi une déforestation du fait de l’extension urbaine va s’élargir à une certaine date. Nous travaillons également sur des applications pour comprendre comment le tramway mis en service à Dijon depuis quelques années a modifié la structure urbaine. Seule une formalisation sous forme de graphe logique peut permettre ce genre d’analyse » explique le chercheur.
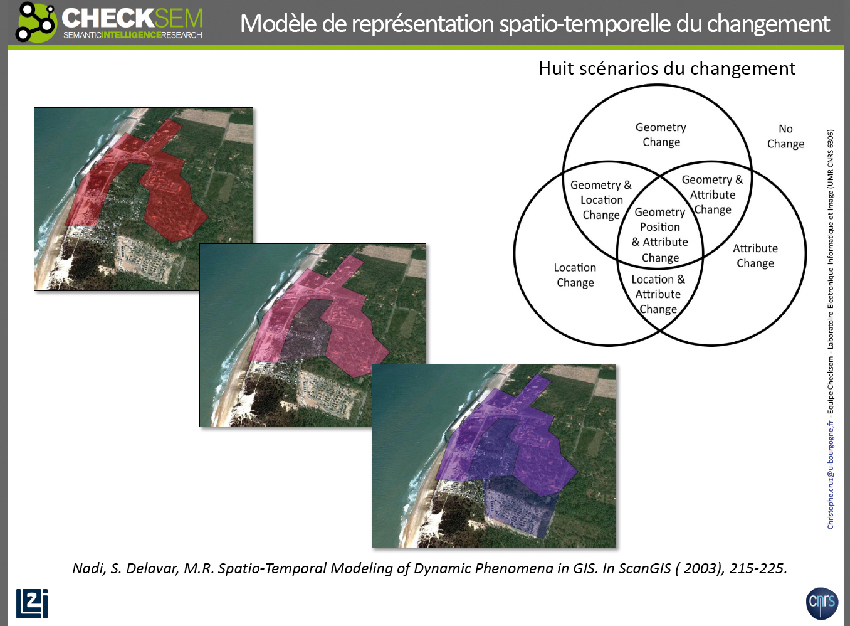
Pour étudier différents scénarios d’évolution spatio-temporelle, l’équipe Checksem de l’université de Bourgogne utilise des modélisations sémantiques.
Mais le Web sémantique ne réglera pas tous les problèmes pour autant. « Il y a plein de dimensions qui ne sont pas abordées par le Web sémantique, notamment sociales, puisque la formalisation proposée ne nous dit rien sur qui utilise les données, analyse Christophe Cruz. C’est un outil supplémentaire de traitement des données. Mais il bute encore sur certains problèmes. On ne sait par exemple pas encore manipuler des graphes très volumineux. La formalisation est tellement précise, que les ontologies deviennent rapidement trop complexes à vérifier. »
Adoptez la Web sémantique attitude
Comment faciliter le Web sémantique ? Des recommandations hiérarchisées ont été émises par le W3C afin de faciliter l’utilisation des données dans le contexte du Web sémantique. Si vous publiez vos données sur le Web sous forme de licence ouverte, vous gagnez une étoile. En cas de format structuré, en plus non propriétaire, vous avez déjà trois étoiles. Il vous faudra utiliser les recommandations du W3C pour obtenir votre quatrième étoile. Mais seules les données liées à d’autres données bénéficieront du score maximal. Seuls neuf jeux de données sont publiés sur data.gouv.fr en format RDF (dont DBpedia qui référence les termes des cartouches de Wikipedia et les codes des divisions administratives de l’INSEE). Manifestement, la France n’est pas encore un hôtel cinq étoiles pour le Web sémantique.
| Vocabulaire |
| Le Web sémantique en quelques acronymes |
| Une URI (Uniform Ressource Identifier) identifie une ressource sur le Web de façon unique et persistante, qui sera aussi bien comprise par des pages html (compréhensibles par des humains) que par des modèles RDF (interprétable par des machines) via le protocole HTTP. « Si les URL permettent d’identifier ce qui existe sur le Web, les URI permettent d’identifier, sur le Web, ce qui existe » résumait Fabien Gandon, chercheur à l’INRIA, lors de la conférence finale du projet Datalift en mars dernier. |
| RDF (Ressource Description Framework) est un modèle de description des ressources (qui peuvent être de toute nature : une page html, un identifiant quelconque, un film, une personne, un lieu…) sous forme d’une assertion reliant un couple sujet/objet par un prédicat. Par exemple : « La fontaine de Diane (sujet) est située (prédicat) à Paris (objet) ». Les différents triplets forment les éléments d’un graphe. « La fontaine de Diane a été construite par Louis Deprez » peut être considéré comme un deuxième arc du graphe. Les trois éléments (sujet, prédicat, objet) sont identifiés sous forme d’URI. On parle également d’architecture Triple Store. |
| RDFS (RDF Schéma) définit les classes de ressources (Paris est un lieu, Louis Deprez est une personne), leurs propriétés et permet d’organiser leur hiérarchie afin de réaliser des inférences simples. |
| OWL (Web Ontology Language) décrit des ontologies. Ces dernières sont un ensemble de primitives décrites en RDF qui étend le vocabulaire RDFS avec des notions de classes définies par union, intersection, complément, équivalence… |
| SKOS (Simple Knowledge Organization System) est un modèle commun pour partager et lier (via RDF) des thesaurus, des index, des vocabulaires… |
| Le langage de requête SPARQL (Sparql Protocol and RDF Query Language) permet de rechercher et de modifier des données RDF. Il est au RDF ce que SQL est aux bases de données relationnelles. |
| Avis d’expert |
 Sylvain Grellet est responsable du programme scientifique « Urbanisation et gestion de l’information géoscientifique » au BRGM. Ce spécialiste de l’interopérabilité au sens OGC, Inspire s’intéresse au Web sémantique depuis 2007. Sylvain Grellet est responsable du programme scientifique « Urbanisation et gestion de l’information géoscientifique » au BRGM. Ce spécialiste de l’interopérabilité au sens OGC, Inspire s’intéresse au Web sémantique depuis 2007. |
| À vos yeux, le Web sémantique est-il un nouveau paradigme ou un outil complémentaire à l’interopérabilité en cours dans les géosciences ? |
| Il ne faut surtout pas mettre les deux sujets dos-à-dos. Les présentations de la journée du 7 octobre ont montré que les approches sont complémentaires et se rapprochent. On nous a vendu le Web sémantique comme une boîte noire hyperflexible qui allait connecter tout à tout. On s’aperçoit aujourd’hui que les choses s’ordonnent et que l’on retrouve certains aspects clés de la normalisation plus classique (OGG, Inspire…) autour de notions telles que celle d’ontologie de référence ou d’opérateurs (curateurs) validant ces ontologies. À mes yeux, c’est une boîte à outils supplémentaire pour mettre la donnée au cœur du système. Si on commence à lier les jeux de données entre eux, on va découvrir des erreurs de saisie, des incohérences et la qualité ne fera qu’augmenter. Mais il va falloir animer ce nettoyage et trouver les bons outils pour permettre aux utilisateurs de plonger dans ces données liées, tant en termes de modèles de données, de performances informatiques que d’interfaces. Là encore, il y a du beau travail en perspective. |
- Pour accéder directement aux présentations de la journée du 7 octobre, suivez ce lien


 Communiqués
Communiqués 




